解読 Scalable and accurate deep learning with electronic health records
Google最新論文(18年)。最近ニュースでも話題になった入院患者の死亡率などを予測する深層学習の論文。 まだ、日本語でちゃんと解説された記事が無かったので、簡単なメモを作成。 間違いや、良くわからん訳などあるかもしれないが、そこはご容赦。
○論文
補足資料(具体的な手法説明)
Supplementary Materials
○ソースコード
- FHIRデータ形式のソース
https://github.com/google/fhir
○関連記事
Googleが病院を訪れた患者の身に「次に何が起こるか?」を予測する技術を開発
https://gigazine.net/news/20180510-deep-learning-for-electronic-health-records/医療情報をクレンジングなしで容易に統合、AIで経過を高精度予測 googleの研究
https://medit.tech/google-and-the-teams-repo/
簡単に言うと
Google+UCサンフランシスコ校+シカゴ薬科大+スタンフォード大の研究チームが、複数の医療機関の電子カルテ(EHR)情報を標準フォーマット(FHIR)で統合し、入院患者の経過(院内死亡、計画外再入院、入院長期化)と退院診断名を深層学習等を用いて予測するアルゴリズムを開発。すべてのタスクにおいて既存手法を上回る精度を達成。これにより、早期(例えば入院後24時間以内)に高リスクの患者を検知しアラートを挙げることで、医療従事者は何らかの対策を打てるようになる。
※全体概念図は下記
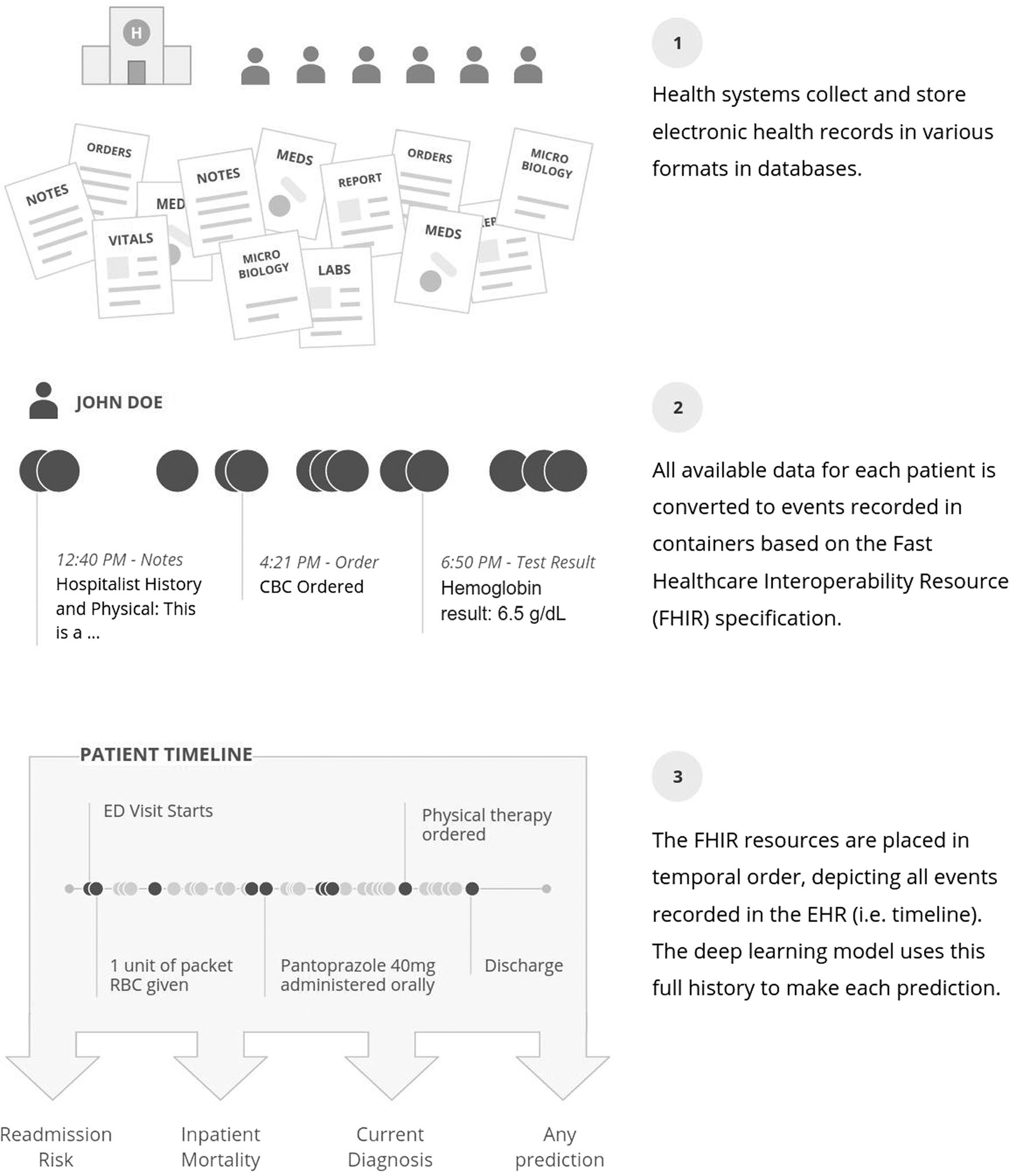
感想
- 転移学習のようなネットワーク側でデータ形式の違いを吸収するのではなく、ネットワークへデータ入力する前に、生データからベクトル化(Embedding)する前処理で吸収。(帰納学習ではなく、表現学習の論文とみると合点がいった)
- 前処理は、標準コード化、正規化、自然言語処理などの様々な手法の組み合わせ。この論文の最も注力した部分であり、後段処理の深層学習に頼らず、各種データの特性に合わせて(愚直に)作り込んでいる印象。
- 推定モデルに関しては、時系列データ向け深層学習(LSTM)、フィードフォワード・ニューラルネットワーク、ブースティングモデルの計3つの(オーソドックスな)手法に並行してデータ入力し、得られた3つの出力から多数決により1つ選ぶ。これを最終的な推定結果とした。
- ベースラインとした手法に、本研究で得た全データのベクトルを入力した場合と、先行事例で扱っていた限定データの特徴量を入力した場合で性能比較。前者の方が後者よりも高い性能を得たことから、本研究のように臨床の様々なデータを余すこと無く使うことが重要であることも示唆。
概要
- EHR生データを全てFHIR形式(下記、参考参照)へ記録し、深層学習などを用いて複数タスク(①患者の院内死亡、②計画外再入院、③入院長期化、④退院診断名)の推定を行った。
- タスクを選んだ理由
- 院内死亡:医療の重要な結果
- 計画外再入院:医療の質を客観評価できる指標
- 入院長期化:医療資源の活用指標
- 退院診断名:患者の問題理解の指標
- 結果
| タスク | 提案手法 | 従来手法 |
|---|---|---|
| 院内死亡 | 0.93~0.94 | 0.85~0.86 |
| 計画外再入院 | 0.75~0.76 | 0.68~0.70 |
| 入院長期化 | 0.85~0.86 | 0.74~0.76 |
| 退院診断名 | 0.90 | - |
評価指標のAUROCは、ROC曲線の面積を表し、1.0に近づく程、精度良い(=TPが多く&FPが少ない)
提案手法は、様々な医療における活用に応用ができる(Scalable & Accurate)推定手法。
イントロ
- 分析コストの約8割がデータクレンジングなど
- フリーテキストをそのまま使うと、FPとFNが問題となる。
- 深層学習の利点は潜在的な推定因子を予め特定しておく必要がないこと。
- 面倒なデータ構造化をせずとも、ダイレクトに深層学習でEHRの生データを扱えると考えた。
関連研究
- 一部データのみ使って推定する研究事例はある
- 複数病院間のデータ標準化はチャレンジングな課題。
- 深層学習の登場によって、EHRデータを扱う研究事例が急増。
- 典型的な例は、オートエンコーダによる特定の診断の予測に利用するもの。
- 時系列データを扱うやり方としては、RNNでイベントを予測するもの。
- フリーテキストを含む全てのEHRデータを扱ったものはなく、どの研究も部分的な特徴しか使っていない。
また、ICUにフォーカスした研究事例もある。
この研究の貢献は下記2点。
- EHR生データを入力でき、FHIR形式で結果出力できるので、業務システムへの組み込みが容易
- ICUなどに特化しない一般患者を対象
結果
- 2つの病院(A, B)の約3年間における約21万件の入院データ(約11万人の患者データ)を対象。
- 入院や退院などのイベント前後における、各タスクの予測精度を従来手法(ベースライン)と比較した結果が下表の通り。
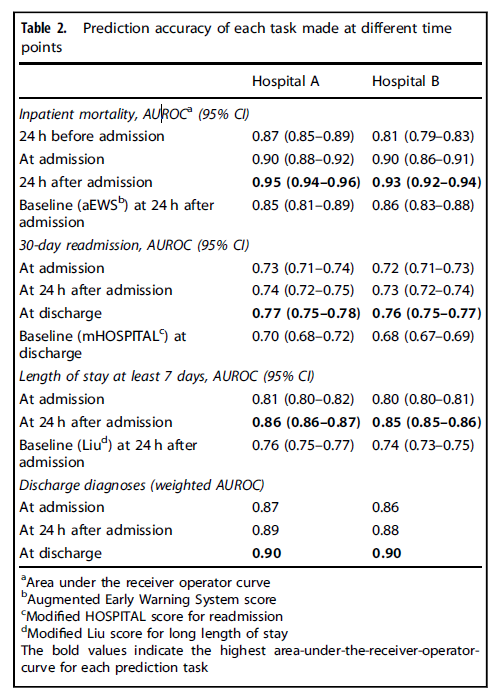
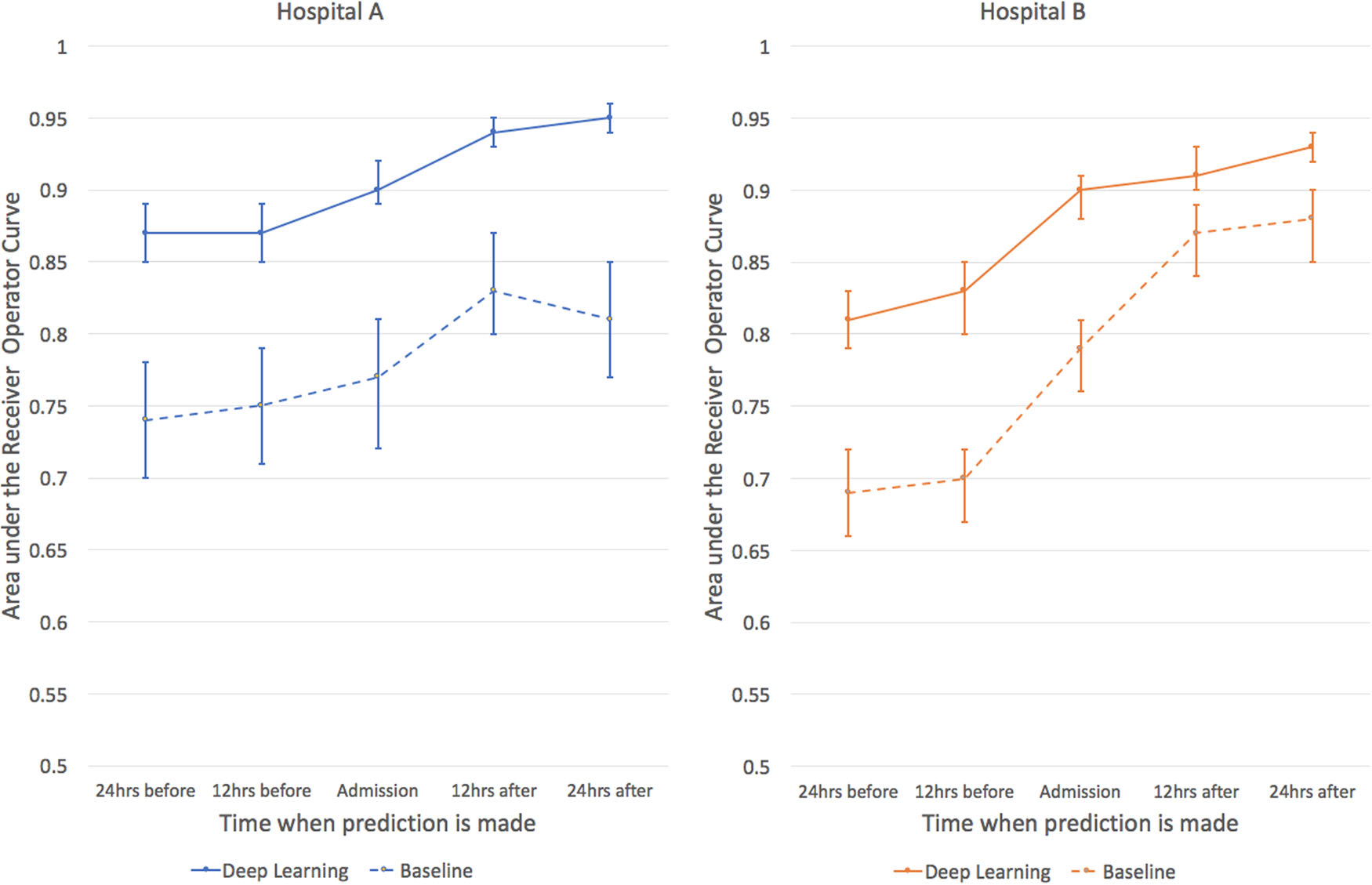
- 院内死亡予測は、ベースライン手法として、28因子のロジスティック回帰モデル(aEWS)を利用。提案手法は、これに対し誤アラートを約半減させた。精度AUROCは下図(実線:提案、破線:従来)。
退院時診断の推定は、ICD-9の病名コード(約1万4千コード)に基づき実施。退院時はAUROC 0.9。ベースラインとなる既存手法は無かったため、比較はなし。
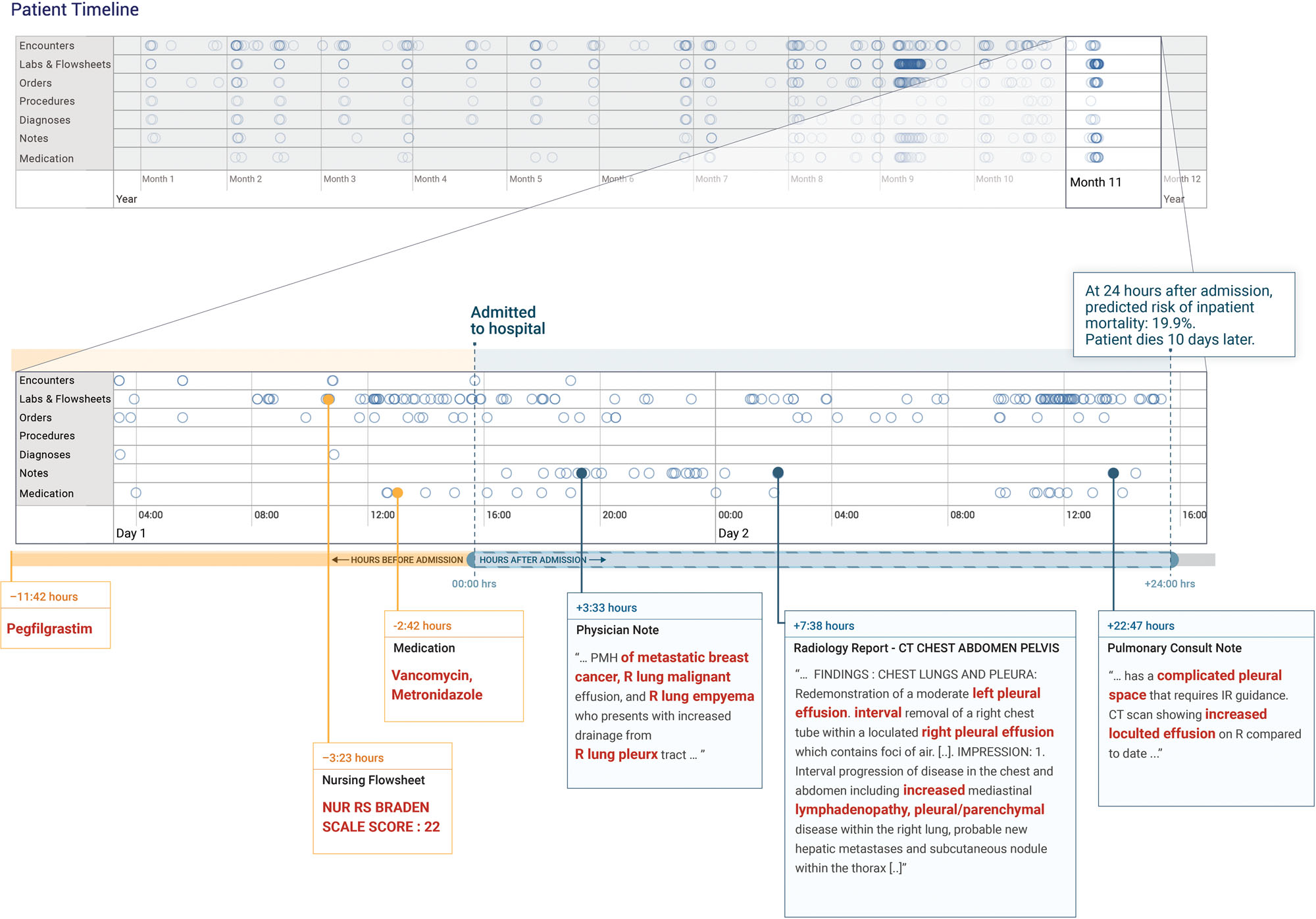
実際に、入院10日後に悪性の胸水と膿胸により患者死亡したケース(下図)では、入院後24時間後に提案手法では死亡リスクが19.9%と予測していたのに対し、従来手法(aEWS)は9.3%であった。
手法
データセットについて
- UCSF 5年分+UCM 8年分のデータを学習に、AおよびB病院のデータをテストに利用(倫理承認を受け、匿名化済み)
- データの種類としては、患者情報、オーダー、診断、処置、投薬、臨床検査値、バイタルサイン、フローシート。
- 数値は正規化。フリーテキストはトークン
(補足)FHIRリソースからトークンへのマッピング手法
※ データ表現についてはSupplementary Materialsが詳しいので、別途ここで説明する。
* ちなみに、本論文では、「Embeddings(埋め込み)」というキーワードがかなり登場する。意味としては下記、論文にあるように、ベクトル化と同義なので「ベクトル化」と訳した。
自然言語処理において Embedding(埋め込み)とは主に,文や単語,文字など自然言語の構成要素に何らかの空間における(実)ベクトルを与えることを指す。
―堅山 耀太郎:Word Embeddingモデル再訪(オペレーションリサーチ 2017年11月号)より
- 例えば、あるオーダー情報をベクトル化する際は、オーダー名+薬剤コード(RxNormコード)を対応づけて、これを1つの要素(特徴)とする。
- 各特徴の値(例えば、アスピリン)は、単一のユニークなトークン(1つの要素の場合)か、連続したトークン(フリーテキストの要素の場合)に対応づける。
- コードの文字表現や、医師名、臨床検査、処置などのその他のテキスト特徴は、最初に空白区切り等でトークン分割し、その後、連続したトークンへ対応づける。
- 数値情報の表現方法は以下の2つのアプローチが考えられる。
- 例えば、名前、値、単位の3つが連結された “ヘモグロビン 12 g/dL” は、1つのユニークなトークンへ
- 分位数(上記の”12”はヘモグロビンの中央値かもしれないが、ヘモグロビンA1cの99番目のパーセンタイルかもしれない)と単位とを連結し、1つのユニークなトークンへ
- 1つの特徴のユニークなトークン(医学的なコードや単語、観測されたパーセンタイル等)は、それぞれd次元の浮動小数点で表現されるベクトルeにする。
- 学習データに少なくとも2回出現するトークンは、ベクトル化する。
- 出現頻度が少ないトークンは、ハッシュ化され、少数の語彙外のベクトルにする。
- 全てのベクトルはランダムに初期化。
- この一連の処理のイメージを以下に図示する。

- 時間の表現は利用するモデル毎に異なるマッピングを行う。
- RNNの場合、時間の対数値を扱い、上限値を決め、次の整数値へ丸める。
- フィードフォワードネットワークの場合、時間を1,2,4,8,…日といった対数増加する”バケツ(bucket)“へ変換する。年齢も同様。
- ブースティングモデルは、離散化の手法として、数千の時間を学習する。
既存手法(ベースライン)について
- 死亡予測:NEWSスコア値+最近の最低血圧・心拍数・呼吸数・体温・臨床検査値(24種)を入力とし、ロジスティック回帰で求める。これを「aEWS(早期警戒スコア)」と名付けて利用。
- 再入院予測:HOSPITALスコアを入力とし、ロジスティックモデルで求める。=「mHOSPITAL」。
- 入院長期化予測:年齢・性別・体調カテゴリ・入院原因・処置・臨床検査値を入力とし、既存研究のLiuらの方法を実装。=「mLiu」
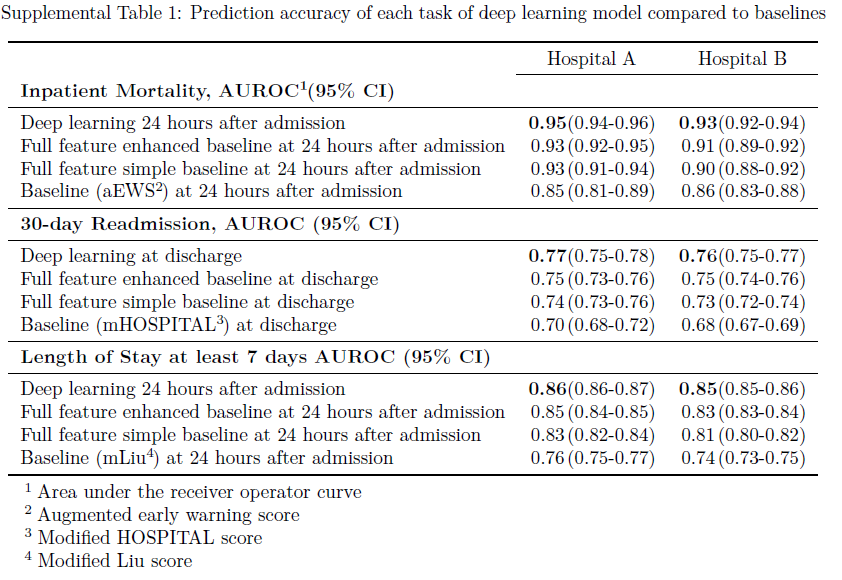
(補足)ベースラインの性能比較
※補足資料によれば、性能値は下記の通り。
提案手法 > 全ての特徴利用した改良版のベースライン > 全ての特徴利用した先行事例のベースライン > 限定された特徴(各タスクに合ったハンドクラフト特徴)を利用した先行事例のベースライン
提案手法について
※原著論文には詳細な説明が無いので、Supplementary Materialsを参照して以下に記載。
- 下記3つの推定モデルを組み合わせて(どのモデルの出力結果を採用するかは、投票で決める)、最終判断を出力。
- 重み付きRNN(シーケンス・モデル)
- 時間を意識したフィードフォワード・モデル
- 時系列モデルを埋め込んだブースティング・モデル
(補足)1. 重み付きRNN(シーケンス・モデル)について
- EHRデータを12時間ごとにイベントを分割。
- n層のRNNとして、LSTM (Long Short-Term Memory network)を利用。LSTMは3つのゲート(忘却ゲート、入力ゲート、出力ゲート)を持ち、次状態のノードに前状態を伝える仕組みを備える。
- LSTMは下記の式で定義。
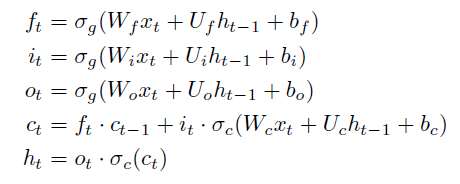
- 第1式 ft:(時刻tにおける)忘却ゲート、σg:シグモイド関数、xt:時刻tの入力、ht-1:時刻t-1の隠れ出力、W,U:重み、b:バイアス
- 第2式 it:(時刻tにおける)入力ゲート、(以下、略)
- 第3式 ot:(時刻tにおける)出力ゲート、(以下、略)
- 第4式 ct:(時刻tにおける)セル状態、σc:双曲線関数、(以下、略)
- 第5式 ht:(時刻tにおける)隠れ出力
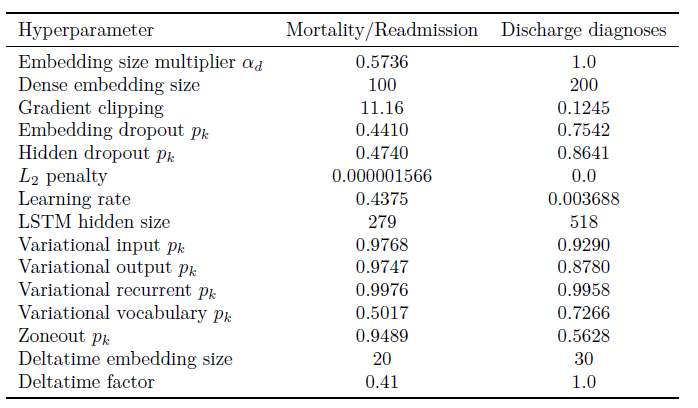
- LSTMのハイパーパラメータは、Adagrad(バイナリ・タスク用の勾配法)とAdam(マルチラベル・タスク用の勾配法)の2つで最適化。その結果は下表の通り。(計算環境はGoogleVizierを利用し、1000回以上の試行で求めた)
(補足)2. 時間を意識したフィードフォワード・モデル
- 連続したベクトル Ei (i=1,…,n)の最初にΔ0=0に対応するE0を追加する。
- このとき、次式で表わされる重みΒiを定義する(ソフトマックスで変換する)。
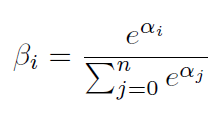
- この重みを掛けた和であるd次元のベクトルE=Σj Βj Ej を、フィードフォーワード・ニューラルネットワークへ入力。
- 下記で示す関数 A(Δ) を定義

- ここで、ベクトルのk次元への写像を、k×d次元の行列Pの学習によって定義。
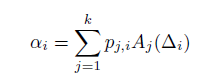
- ベクトル化の次元dは、16~512の範囲。NNのレイヤー数は0~3(※10~512の幅を持ったネットワーク)
(補足)3. 時系列モデルを埋め込んだブースティング・モデル
- bigrams, trigrams, 4-gram トークンを全てのトークン化された特徴から作成。
- 各特徴タプル(トークン名、値、時間)について、2クラスに分類するバイナリ決定ルール(下記)を作成。
- (ルール1) 患者のタイムライン上のどこかの時点に変数Xが存在するか否か。
- (ルール2)患者のタイムラインにC回以上変数Xが存在するか否か。Cはデータセット中の各変数が取り得る整数値の範囲からランダムにピックアップされたもの。
- (ルール3)任意の時点t(但しt
V かつ t<T、もしくは、x≦V かつ t<T)があるか否か。ここで、VとTは上記同様に、データセット中の取り得る値域からピックアップされたもの。 - (ルール4)ルール3の変更版。単純なバイナリ判断ではなく、x<Vとなる回数の重み付き合計値。重みはTの因子の時間減衰に応じたHawkes process(確率的点過程モデルの1つ)によって決まる。このバイナリルールは重み付き合計値が(ランダムユーザーから選択されたA templatesよりも大きいA instance となるような)活性度 Aよりも大きいかどうか試験をすることで作成される。 VとTを選ぶために、 あるテンプレートインスタンスのランダム選択を使う。このとき、Aは次式でインスタンスから計算できる。
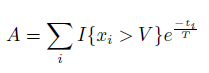
- (ルール5)変数Xの”最小値”が、時刻t(但しt<T)におけるVよりも大きいか否か。
- (ルール8)変数Xの”最大値”が、時刻t(但しt<T)におけるVよりも大きいか否か。
- (ルール7)変数Xの”平均値”が、時刻t(但しt<T)におけるVよりも大きいか否か。
- (ルール8,9)臨床検査値(例えば血圧など)が時間と共に変化することを捉えたルール。具体的には、ルール8は”変化の加速度”(ある時間窓で分割したときの変化量)が閾値Vよりも大きい/小さいか否か。ルール9は、”時間T以内の変位”が閾値Vよりも大きい/小さいか否か。
- (ルール10)前記推定の結合ルール。(例えば、X1が存在し、かつ、C2より大きなX2の回数)。これら決定リストを”述語(predicates)“と呼び、決定木の正の枝を辿ったものと同義。
(参考)HL7 FHIRについて
- まず、HL7協会が診療情報交換のために診療⽂書(Clinical Document)を構造的及び意味的に記述する規約(XMLで記述)をHL7 CDA(Clinical Document Architecture)で定義。
- FHIRは、これまでのHL7 V2,V3 およびCDA各標準仕様の⼀番良い部分を活かしつつ最新のWEB標準(RESTFull WebAPI等)に対応することで、実装のしやすさに重点が置かれているデータフォーマット。

